




In the first post, I wanted to set the context for global scale issues. This blog series is theoretical but I’m pretty sure everyone sympathies with this example.
XP is still running globally. It’s still delivering real experiences. And for many teams, it is a global platform.
The first step in operating XP at scale isn’t a massive re-architecture.
It’s much simpler.
Put your content delivery closer to your customers.
Single-region delivery creates invisible friction
Most XP platforms start in one region and that’s sensible early on.
It keeps infrastructure simple and cost predictable.
But once your audience becomes global, that decision can start to show strain on core web vitals.
- Every request travels back to one geography.
- Rendering happens in one region.
- Every spike hits the same App Service.
Performance starts to feel inconsistent depending on where users are located. Even if the platform is healthy, distance adds latency and varied performance.
Nothing is broken. But everything feels slightly heavier than it should.
Regional Content Delivery (CD) changes the experience immediately
Instead of running one central delivery footprint, you introduce regional CD environments.
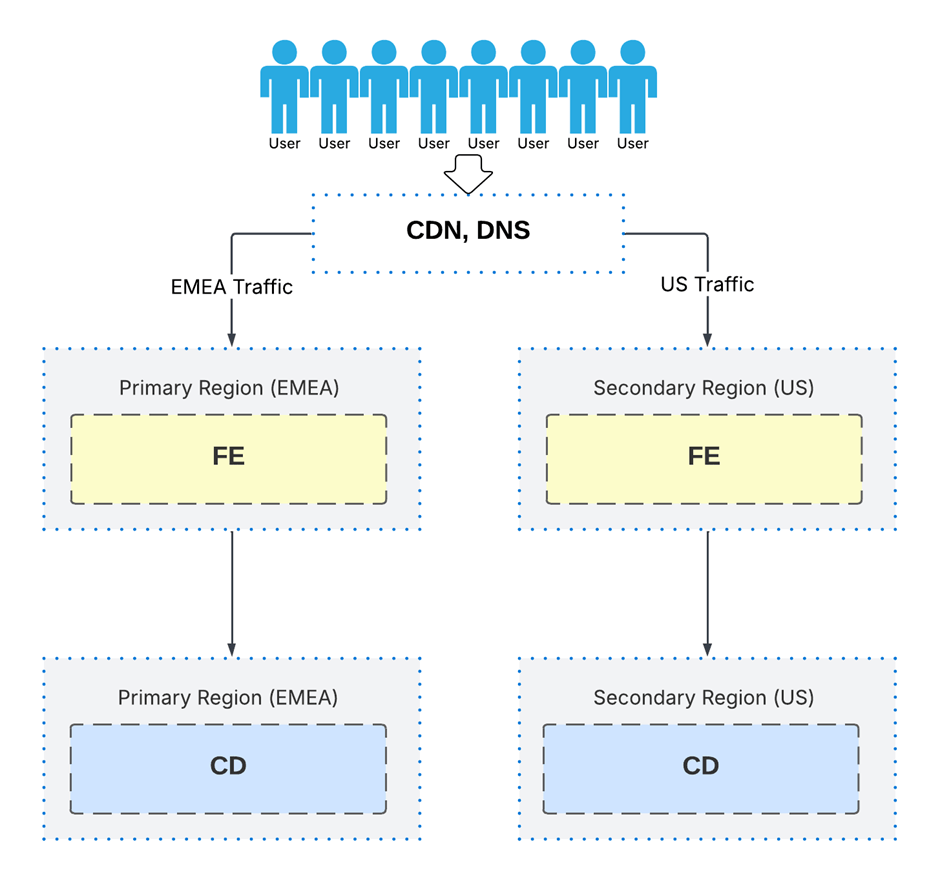
Users in each geography connect to a delivery layer that is physically closer to them. Requests travel less distance. Rendering happens locally. Latency drops. Performance has more stability.
This isn’t about high availability yet.
It’s about proximity.
And proximity alone improves the experience more than most optimisation work.
The above has issues which will cover in the next posts. However it has got content closer to the customer.
Keeping content consistent across regions
Once delivery exists in more than one region, the next concern is obvious.
How do both environments stay in sync?
This is where Sitecore’s existing publishing model works in your favour as content is authored once. Publishing an item pushes updates to the web database.
Both regions receive the same published state.
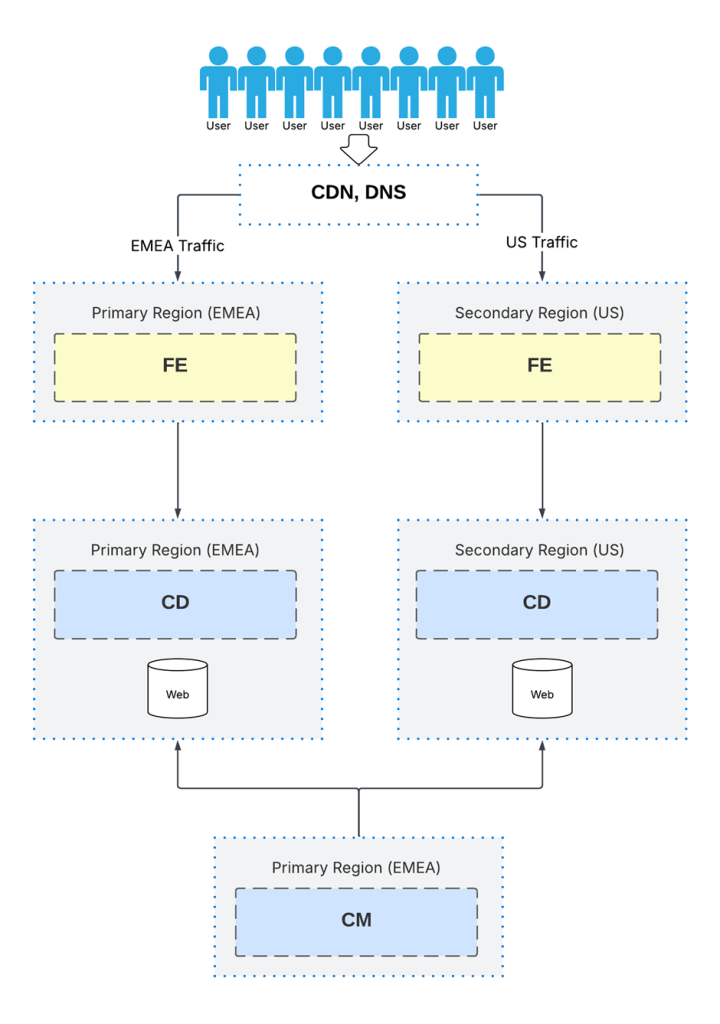
Either use the Sitecore Publishing Service here or SQL database geo replication. Outcome is the same but publishing service will reduce strain on the CM and give a better experience.
You’re not managing two platforms. You’re managing one publishing pipeline feeding multiple delivery endpoints.
Scaling delivery within each region
Once you introduce regional CDs, each one needs to stand on its own operationally.
Each region should run:
- A minimum instance count for stability
- Auto scale rules based on load
- Independent health monitoring
This ensures each geography can handle its own traffic spikes without relying on another.
Azure App Service makes this relatively straightforward. You define baseline capacity so the platform never drops below a stable level, then allow autoscale to handle peaks.
Traffic spikes in one geography stay contained within that geography.
Let Azure remove unhealthy instances automatically
Not all instability happens at the regional level. Sometimes a single instance becomes unhealthy.
CPU spikes
Memory pressure builds
Thread pools stall
Azure health checks allow App Services to automatically remove those instances from rotation. The platform recovers without manual intervention.
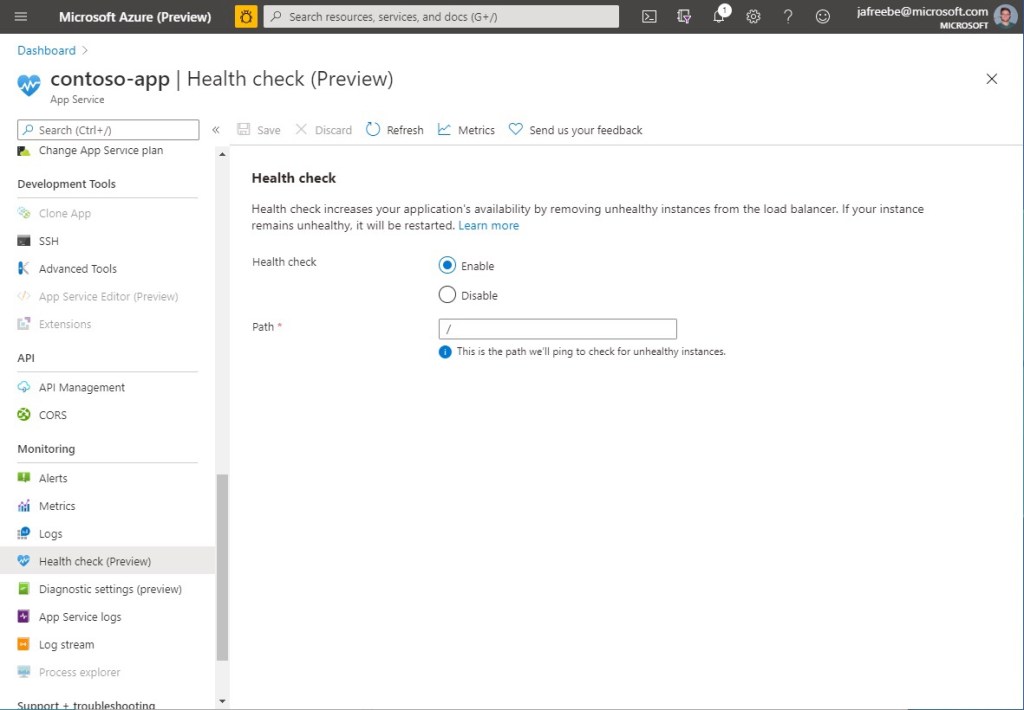
This is one of the simplest but most effective resilience improvements you can make. It prevents minor infrastructure issues from turning into visible delivery problems.
Over time, these small protections make the platform feel far more stable.
With Sitecore you have a few different urls to monitor, for me the most stable is /healthz/live
The impact is bigger than it sounds
Nothing here is dramatic.
You haven’t introduced global routing yet.
You haven’t redesigned XP.
You haven’t added new platform layers.
You’ve simply:
- Moved delivery closer to users
- Added a new CD into another region
- Kept content in sync via publishing
- Give each region the autonomy to scale independently
And yet the effect is immediate.
Performance improves.
Instability becomes localised instead of global.
The platform begins to behave like something designed for global delivery.
This is the foundation for everything that follows
You’ve improved proximity.
You’ve reduced regional pressure.
You’ve contained instability.
But here’s the truth.
As soon as you introduce multiple regions, the platform becomes harder to manage.
Before you introduce global routing or failover logic, you need to be able to see what’s happening.
That’s where the next step comes in.
In the next post, I’ll focus on observability.
Because multi-region delivery without visibility isn’t resilience.
It’s just complexity.


Leave a Reply